



Github – Borisdayma/Dalle -Mini: Dall · E Mini – Generer bilder fra en tekstprompt, hvordan fungerer Dalle -Mini?
Hvordan fungerer dalle-mini
Hvis ingenting skjer, last ned GitHub Desktop og prøv igjen.
Lagrede søk
Bruk lagrede søk for å filtrere resultatene raskere
Avbryt Opprett lagret søk
Du logget på med en annen fane eller vindu. Last på nytt for å oppdatere økten. Du meldte deg ut i en annen fane eller vindu. Last på nytt for å oppdatere økten. . Last på nytt for å oppdatere økten.
Dall · e mini – generere bilder fra en tekstprompt
Tillatelse
Borisdayma/Dalle-Mini
Denne forpliktelsen tilhører ikke noen gren på dette depotet, og kan tilhøre en gaffel utenfor depotet.
Kunne ikke laste grener
Navn allerede i bruk
En tag eksisterer allerede med det medfølgende grennavnet. Mange GIT -kommandoer godtar både tag- og grennavn, så det kan forårsake uventet atferd for å lage denne grenen. ?
- Lokal
- Codespaces
Bruk git eller kasse med SVN ved hjelp av nettadressen.
Arbeid raskt med vår offisielle CLI. .
Logg på nødvendig
Vennligst logg på for å bruke kodespaser.
Lansering av GitHub Desktop
Hvis ingenting skjer, last ned GitHub Desktop og prøv igjen.
Hvis ingenting skjer, last ned GitHub Desktop og prøv igjen.
Lansering av Xcode
.
Lansering av Visual Studio Code
Codespace vil åpne en gang klar.
Det var et problem med å forberede kodespace, prøv igjen.
Siste forpliktelse
Git statistikk
Filer
.
Siste forpliktelsesmelding
30. november 2021 04:47
23. oktober 2022 17:35
30. november 2021 04:38
30. november 2021 04:14
Readme.MD
Dall · e mini
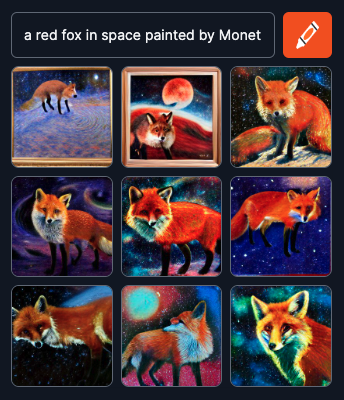
?
Du kan bruke modellen på �� craiyon
Hvordan virker det?
Se rapportene våre:
- Dall · e mini – generere bilder fra hvilken som helst tekstprompt
- Dall · e mini – forklart
- Dall · E Mega – Training Journal
Utvikling
Avhengighetsinstallasjon
Bare for inferens, bruk pip install dalle-mini .
For utvikling, klon repoen og bruk Pip Install -e “. . .
Trening av dall · e mini
.
FAQ
Hvor du kan finne de nyeste modellene?
- Dall · e mini eller dall · e mega for å generere bilder fra en tekstprompt
Hvor kommer logoen fra?
“Lenestolen i form av en avokado” ble brukt av Openai når du slapp Dall · E for å illustrere modellens evner. Å ha vellykkede spådommer om denne ledeteksten representerer en stor milepæl for oss.
. Ethvert bidrag er velkomne, fra rapporteringsproblemer til å foreslå rettelser/forbedringer eller teste modellen med kule spørsmål!
Du kan også bruke disse gode prosjektene fra samfunnet:
- Spin av din egen app med Dall-E Playground Repository (takk Sahar)
- Prøv Dall · E Flow Project for å generere, diffusjon og oppskalering i en arbeidsflyt for human-in-the-loop (takk Han Xiao)
- Kjør på replikat, i nettleseren eller via API
Anerkjennelser
- �� Hugging ansikt for å organisere lin/jax samfunnsuke
- Vekter og skjevheter for å gi infrastruktur for eksperimentsporing og modellstyring
Forfattere og bidragsytere
Dall · e mini ble opprinnelig utviklet av:
- Dalle-Pytorch og Eleutherai-samfunnene for testing og utveksling av kule ideer
- Rohan Anil for å legge til distribuert sjampooptimisator og alltid gi gode forslag
- Phil Wang har gitt mange kule implementeringer av transformatorvarianter og gir interessant innsikt med X-Transformers
- Katherine Crowson for superkondisjonering
- Gradio -teamet laget en fantastisk brukergrensesnitt for appen vår
Siterer dall · e mini
Hvis du finner dall · e mini nyttig i forskningen din eller ønsker å henvise, kan du bruke følgende Bibtex -oppføring.
@Misc, doi =, måned =, tittel =, url =, år => Referanser
- “Glu -varianter forbedrer transformatoren”
- “Swin Transformer: Hierarkisk synstransformator ved hjelp av skiftede vinduer”
- “Root Mean Square Layer Normalization”
- “Sinkformers: Transformers med dobbelt stokastisk oppmerksomhet”
- “Foundation Transformers
Sitasjoner
@Misc< title=, author=, year=, eprint=, archivePrefix=, primaryClass= > < title=, author=, year=, eprint=, archivePrefix=, primaryClass= > < title=, author=, year=, eprint=, archivePrefix=, primaryClass= > @Misc< title=, author=, year=, eprint=, archivePrefix=, primaryClass= > < title=, author=, year=, eprint=, archivePrefix=, primaryClass= > @Misc< title=, author=, year=, url= > < title=, author=, year=, eprint= archivePrefix=, primaryClass= > @Misc< title=, author=, year=, eprint=, archivePrefix=, primaryClass= > @inproceedings< title=, author=, booktitle=, year= > @Misc< title = , author = , year = , eprint = , archivePrefix = , primaryClass = > @Misc< title = , author = , year = , eprint = , archivePrefix = , primaryClass = > < title = , url = , author = , publisher = , year = , > @Misc< title = , url = , author = , publisher = , year = , > @Misc< title = , url = , author = , publisher = , year = , > Dall · e mini – generere bilder fra en tekstprompt
?
Dalle Mini er en gratis, open source AI som produserer fantastiske bilder fra tekstinnganger. Slik fungerer det.
Louis Bouchard
15. juni 2022 • 4 min lest

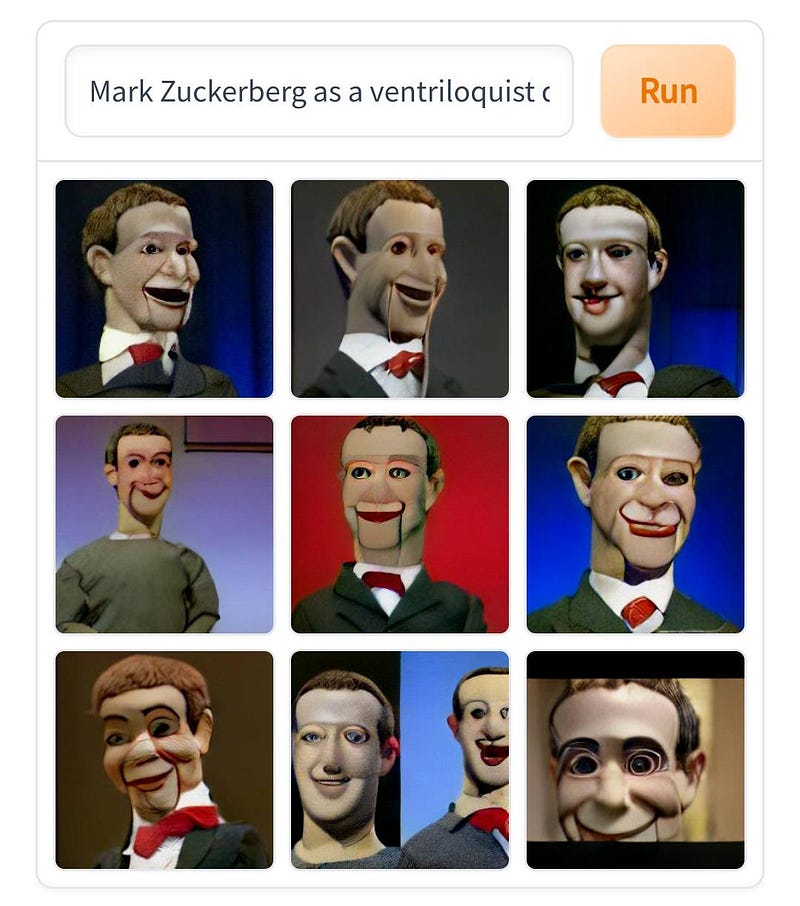
Jeg er sikker på at du har sett bilder som de i Twitter -feeden din de siste dagene. Hvis du lurte på hva de var, er de bilder generert av en AI som heter Dall · E Mini. Hvis du aldri har sett dem, må du lese denne artikkelen fordi du går glipp av det. Hvis du lurer på hvordan dette er mulig, vel, er du med på den perfekte artikkelen og vil vite svaret på mindre enn fem minutter.
Dette navnet, Dall · E, må allerede ringe en bjelle da jeg dekket to versjoner av denne modellen laget av Open AI det siste året med utrolige resultater. Men denne er annerledes. Dall · E Mini er et åpen kildekode-skapt prosjekt inspirert av den første versjonen av Dall · E og har holdt på å utvikle seg siden den gang, med nå utrolige resultater takket være Boris Dayma og alle bidragsytere.
Ja, dette betyr at du kan leke med det med en gang, takket være Huggingface.
Koblingen er i referansene nedenfor, men gi denne artikkelen noen sekunder til før du spiller med den. Det vil være verdt det, og du vil vite mye mer om denne AI enn alle du kjenner rundt deg.

I kjernen er dall · e mini veldig lik dall · e, så min første video på modellen er en flott introduksjon til denne. Den har to hovedkomponenter, som du mistenker, et språk og en bildemodul.
For det første må den forstå tekstpromptet og deretter generere bilder etter den, to veldig forskjellige ting som krever to veldig forskjellige modeller. De viktigste forskjellene med dall · e ligger i modellens arkitekturer og treningsdata, men ende-til-ende-prosessen er stort sett den samme. Her har vi en språkmodell som heter BART. Bart er en modell som er opplært til å transformere tekstinngang til et språk som er forståelig for neste modell. Under trening mater vi par av bilder med bildetekster for å dall · e mini. Bart tar tekstbildet og forvandler den til diskrete symboler, og vi justerer den basert på forskjellen mellom det genererte bildet og bildet som er sendt som inngang.
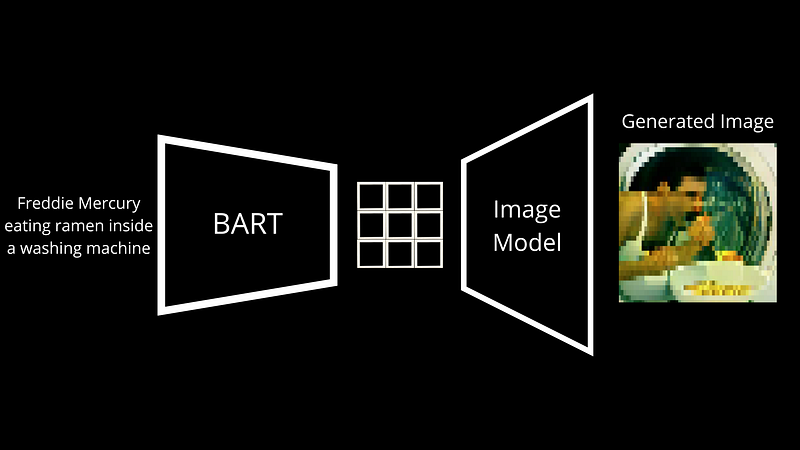
? Vi kaller dette en dekoder. Det vil ta denne nye bildetekstrepresentasjonen produsert av Bart, som vi kaller en koding, og vil avkode den i et bilde. I dette tilfellet er bildekoderen Vqgan, en modell jeg allerede dekket på kanalen, så jeg inviterer deg definitivt til å se den hvis du er interessert.
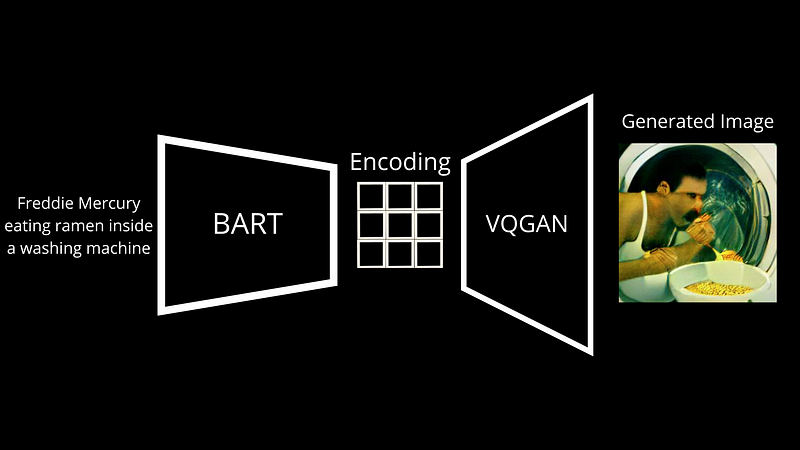
Kort sagt, Vqgan er en flott arkitektur for å gjøre det motsatte. Den lærer hvordan du går fra en slik kodingskartlegging og genererer et bilde ut av det. Som du mistenker, gjør GPT-3 og andre språkgenerative modeller en veldig lignende ting, koder for tekst og avkoder den ny genererte kartleggingen til en ny tekst som den sender deg tilbake. Her er det den samme tingen, men med piksler som danner et bilde i stedet for bokstaver som danner en setning. Den lærer gjennom millioner av kodingsbildepar fra Internett, så i utgangspunktet de publiserte bildene dine med bildetekster, og ender opp med å være ganske nøyaktig når det gjelder å rekonstruere det første bildet.
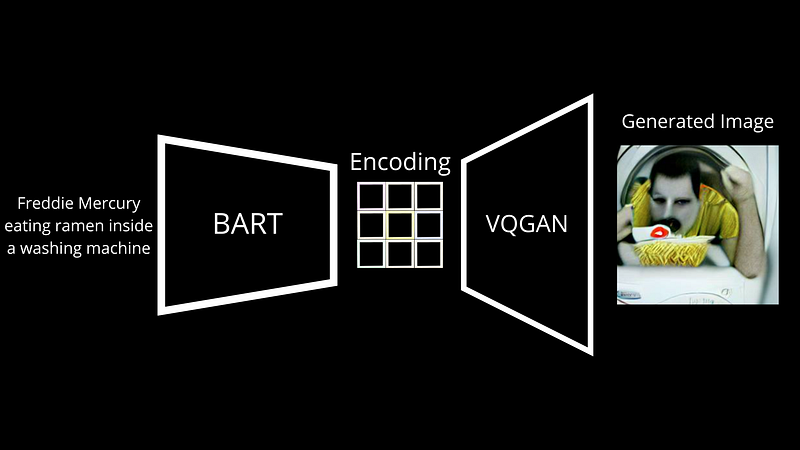
. Tilsvarende legger vi vanligvis litt støy til disse kodingene for å generere et nytt bilde som representerer samme tekstprompt.
Og voilà! Slik lærer Dall · e mini å generere bilder fra tekstbildene dine.
Som jeg nevnte er det åpen kildekode, og du kan til og med leke med den med en gang, takket være Huggingface. Dette var selvfølgelig bare en enkel oversikt, og jeg utelatt noen viktige trinn for klarhet. Hvis du vil ha flere detaljer om modellen, koblet jeg gode ressurser i referansene nedenfor. .
Det er ganske kult å se!
Jeg håper du likte denne artikkelen og videoen, og i så fall, ta noen sekunder å gi meg beskjed i kommentarene og legg igjen lignende.
Jeg ser deg, ikke neste uke, men om to uker med et annet fantastisk papir!
Bli med i vår Discord Channel, lær AI sammen:
►https: // uenighet.GG/LearnaitTogether
Registrer deg for mer som dette.

Tilpasse LLM -er for å utføre spesifikke oppgaver!
Øke AI-ytelsen med finjustering
Louis Bouchard 19. september 2023 • 6 min lest

MVDREAM: Å lage naturtro 3D -modeller fra ord
MVDREAM: En ny tekst-til-3D-tilnærming (forklart)!
Louis Bouchard 10. september 2023 • 6 min lest

Ai dyp læring forklart
Dyp læring med en enkel analogi
Dall-e mini
Dall-E 2 er banebrytende forskning fra Openai som forfølger det iboende løftet om teknologi: slik at normale mennesker kan skaffe seg supermaktene til de talentfulle og rike. . De som ikke kan annet enn å ha penger, kan ansette fagpersoner. Lokken av Dall-E 2 bevæpner hver person, uavhengig av dyktighet eller inntekt, med de uttrykksfulle evnene til profesjonelle kunstnere.
Varm kjele.AI tilbyr en enkel måte for forbrukerne å utforske og utnytte kraften til AI -bildegeneratorer.
.
AI hodeskuddgenerator
Reimagine deg selv med AI. Lag AI -selfies, AI -hodeskudd, bedriftsbilder og glamourbilder av deg selv i forskjellige stiler og scener. Perfekt for sosiale medieprofiler, dating -apper, LinkedIn -profiler, eller bare se deg selv på en ny måte.
Ai art
Fremskritt innen kunstig intelligens lar alle lage kunst med enkle instruksjoner, omtrent som å instruere en menneskelig kunstner. .
.AI, og Openai, disse AI -bildemodellene kan forstå enkle instruksjoner og produsere bilder – likt hvordan menneskelige kunstnere får instruksjoner fra lånetakerne. Men er denne kunsten eller til og med intelligens?
. . Kan AI hjelpe til?
.